
You’ve probably watched A Bug’s Life or any other cartoon showing how the union of small parts can create something extraordinary. You can also apply this concept in the business and technology world. An edge cluster is an outstanding example of bringing CPU, servers, and edge computers together to create a faster and more reliable computing environment.
As IoT applications usually require low-cost computers that process thousands, or even millions of daily requests and information from many devices, implementing an IoT edge cluster could solve many of the challenges your application might face along the way.
Even though you can implement clusters on the cloud, there are numerous reasons that clusters can be an excellent option for edge computing. Among them, scaling up and processing more data without storing it in the cloud can notably help maintain regulatory compliance and data residency.
Another main factor is that edge clusters can be highly available due to redundancy options, as well as the ability to add and replace nodes.
What is a cluster?
Clusters are groups of independent nodes working together to achieve a common goal. The nodes are either computers or servers, and you can build a cluster using any computer, from the simplest to the most advanced hardware.
One important thing to note is that your clusters are more likely to be more resilient and work better if all computers have the same configuration.
How does it work?
A cluster system will divide the requests or tasks among different nodes, avoiding the system from overloading one computer since it will balance out the workload.
The ideal cluster system would keep all the computers working at the same capacity.
On clusters that house software with client-server architecture, such as HTTP, TCP, UDP, MQTT, and Socket, there should typically be a load balancing system in front of the nodes to orchestrate the requests and distribute the request load between all nodes using algorithms, as well as check the nodes’ availability.
Some clustering algorithms have an election mechanism to elect a head node; the head node will then share parameters and settings with other cluster members. It is the “source of truth” for all members, and this means that when some settings change, all members must change accordingly.
Differentiating clusters
There are many points of view that you can use to differentiate a computer cluster from another. We will only talk about their topology, and the two most common cluster topologies in the market today are star and mesh.
A mesh topology is composed of multiple nodes that are all interconnected with each other, this type of cluster is used when you want all the nodes to have the same availability, meaning that if one of them breaks, the other will take over.
A star topology, on the other hand, is composed of a central leader node that connects all the others; this type of cluster is used when you want to have a control point for your network, or if you don’t want all of your nodes to be impacted when one of them fails.

What do people look for when they use an edge cluster?
As previously stated, clusters offer many features that people look for in edge computing. We selected five to discuss: load balancing, high availability, high performance, redundancy, and scalability.
Cluster load balancing
Load balancing is a technology that distributes the workload evenly across all nodes in a system; it ensures that no single node is overloaded, which is crucial.
There are many load balancing algorithms and technique options in the market. Examples would include:
-
Round-robin: The most basic one; requests are distributed sequentially across the group of servers.
-
Resource-based: This one uses specialized software on each node to check available CPU and memory to choose the best.
-
Weighted Response Time: This algorithm will choose the node that answers a health check the fastest.
-
Least Connections: As the name suggests, the system sends requests to the node with the least amount of connections.
-
Random: Once again, the name says it all. This algorithm distributes requests randomly, yet evenly among the nodes.
High availability
One of the purposes of clusters is to provide a high availability of services. If any node or server fails, the others will continue working to keep the service running. This quality is often essential in mission-critical applications.
High performance
One logical outcome of using five computers to do the job of one is to increase performance. Edge environments will take advantage of this since the hardware is usually weaker, and in some cases, they can’t process data on the cloud.
Redundancy
This one is curious, as even if your system doesn’t need all the other features presented, it might need this one. When part of your application is vital or must not stop for any reason, having a cluster system can be a viable solution. If one of the nodes breaks, the load balancing system will direct the request, or the data, to another computer.
Scalability
Scalability is the ability of a system to increase or decrease its capacity as demand requires. It’s probably one of the main reasons people use clusters since they are composed of multiple nodes that can be added or removed without affecting the availability of the service.
Implementing an IoT edge cluster
Scalability, high redundancy, high performance, and high availability are all excellent reasons to implement a cluster inside your IoT application, but how do you do that?
The first step is to understand what your specific requirements are. In this case, we need a system where any node can process data and requests independently. We also need a way to keep adding nodes as our application grows without affecting its availability.
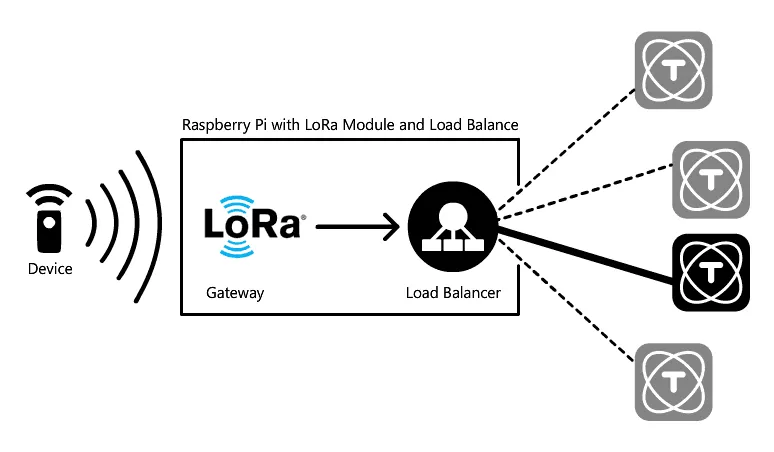
We have implemented a cluster inside TagoIO’s labs. The image below shows our cluster with three ROCK PI 4s working as nodes running TagoCore and one Raspberry Pi running a load balance (Ngnix) which is also a LoRa gateway.

The TagoCore cluster mode uses TagoIO as a “head node.” No device request will be sent to the cloud, and the cluster only uses the TagoIO service to sync settings and as a message bridge between nodes. It is extraordinarily easy to deploy a cluster on the edge; check out the diagram below:
How can TagoIO help?
When you are running TagoCore as a cluster, all instances are synchronized, which means that when you install a plugin in one instance, all other instances will also install it. If you change any configuration, that configuration will replicate on every node on your cluster as well.
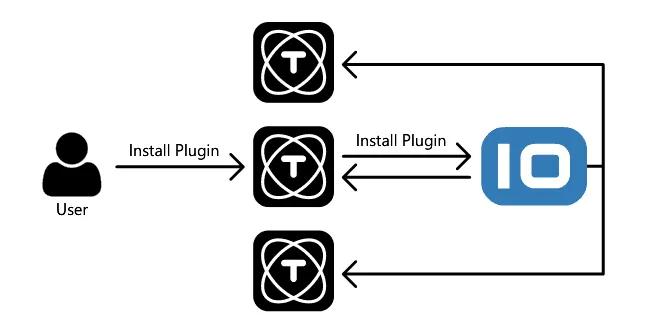
With TagoCore’s cluster feature, the TagoIO cloud service is responsible for managing and syncing every instance on your cluster. This makes it easy to deploy a cluster anywhere without the pain of setup and maintenance of cluster infrastructure. Every new instance you start using the cluster feature will sync and be ready to start receiving requests.
Also, the instance does not need to be in the same infrastructure, meaning that you can easily distribute your cluster instance between regions and different cloud or on-premise machines.
As no device request is forwarded to the TagoIO cloud, you will need to set up a load balance by yourself. To do this, you can use Apache service, Nginx, AWS ELB, and others.
Want to know more?
For more information about TagoCore, check out our webinar “Installing and Configuring TagoCore on edge devices” and visit TagoCore’s page.
TagoCore users can effortlessly implement a cluster inside their on-premise IoT environment, so make sure to take advantage of our open source platform with cluster features! Want to go even further? Show off the data collected using your instances of TagoCore on dashboards using TagoIO cloud platform or distribute it to your clients using TagoRUN, our whitelabel platform, without storing device data in the cloud.
Only with TagoCore do you have data control, security, privacy, reliability, and ease of use. Last but not least, it’s Open Source!


