
Vous avez sans doute vu 1001 pattes ou un autre dessin animé qui montre comment l’union de petits éléments peut donner naissance à quelque chose d’extraordinaire. Ce principe s’applique aussi au monde de l’entreprise et de la technologie. Un edge cluster est un excellent exemple : il rassemble des CPU, des serveurs et des ordinateurs edge pour créer un environnement de calcul plus rapide et plus fiable.
Comme les applications IoT exigent en général des ordinateurs bon marché capables de traiter des milliers, voire des millions de requêtes et d’informations quotidiennes provenant de nombreux appareils, mettre en place un edge cluster IoT peut résoudre une bonne partie des difficultés que votre application rencontrera en chemin.
Même si vous pouvez déployer des clusters dans le cloud, de nombreuses raisons font des clusters une excellente option pour l’edge computing. Parmi elles, la possibilité de monter en charge et de traiter davantage de données sans les stocker dans le cloud aide sensiblement à respecter la conformité réglementaire et la résidence des données.
Autre facteur important : les edge clusters peuvent offrir une haute disponibilité grâce aux options de redondance, ainsi qu’à la possibilité d’ajouter et de remplacer des nodes.
Qu’est-ce qu’un cluster ?
Les clusters sont des groupes de nodes indépendants qui travaillent ensemble pour atteindre un objectif commun. Les nodes sont des ordinateurs ou des serveurs, et vous pouvez construire un cluster avec n’importe quel ordinateur, du matériel le plus simple au plus avancé.
Un point important : vos clusters ont plus de chances d’être résilients et de bien fonctionner si tous les ordinateurs partagent la même configuration.
Comment ça marche ?
Un système de cluster répartit les requêtes ou les tâches entre différents nodes, ce qui évite de surcharger un seul ordinateur puisqu’il équilibre la charge de travail.
Le système de cluster idéal maintiendrait tous les ordinateurs à la même capacité de travail.
Sur les clusters qui hébergent des logiciels à architecture client-serveur, comme HTTP, TCP, UDP, MQTT et Socket, il devrait normalement y avoir un système de répartition de charge en amont des nodes pour orchestrer les requêtes et répartir la charge entre tous les nodes à l’aide d’algorithmes, et vérifier la disponibilité des nodes.
Certains algorithmes de clustering disposent d’un mécanisme d’élection pour désigner un head node ; ce head node partage ensuite les paramètres et réglages avec les autres membres du cluster. Il est la « source de vérité » pour tous les membres, ce qui signifie que lorsqu’un réglage change, tous les membres doivent changer en conséquence.
Différencier les clusters
On peut adopter de nombreux points de vue pour distinguer un cluster d’ordinateurs d’un autre. Nous parlerons uniquement de leur topologie, et les deux topologies de cluster les plus répandues sur le marché aujourd’hui sont star (en étoile) et mesh (maillée).
Une topologie mesh est composée de plusieurs nodes tous interconnectés entre eux. Ce type de cluster sert lorsque vous voulez que tous les nodes aient la même disponibilité : si l’un d’eux tombe en panne, un autre prend le relais.
Une topologie star, à l’inverse, repose sur un node leader central qui relie tous les autres. Ce type de cluster sert lorsque vous voulez disposer d’un point de contrôle pour votre réseau, ou lorsque vous ne voulez pas que tous vos nodes soient affectés quand l’un d’eux tombe en panne.

Que recherchent les gens lorsqu’ils utilisent un edge cluster ?
Comme indiqué précédemment, les clusters offrent de nombreuses fonctionnalités recherchées dans l’edge computing. Nous en avons retenu cinq pour en parler : la répartition de charge, la haute disponibilité, la haute performance, la redondance et l’évolutivité.
Répartition de charge du cluster
La répartition de charge est une technologie qui distribue uniformément la charge de travail entre tous les nodes d’un système ; elle garantit qu’aucun node n’est surchargé, ce qui est essentiel.
Le marché propose de nombreux algorithmes et techniques de répartition de charge. En voici quelques exemples :
-
Round-robin : le plus basique ; les requêtes sont distribuées de façon séquentielle entre le groupe de serveurs.
-
Basé sur les ressources : il utilise un logiciel spécialisé sur chaque node pour vérifier le CPU et la mémoire disponibles et choisir le meilleur.
-
Temps de réponse pondéré : cet algorithme choisit le node qui répond le plus vite à un contrôle de santé.
-
Moins de connexions : comme son nom l’indique, le système envoie les requêtes au node qui compte le moins de connexions.
-
Aléatoire : là encore, le nom dit tout. Cet algorithme distribue les requêtes de manière aléatoire, mais uniforme entre les nodes.
Haute disponibilité
L’un des objectifs des clusters est d’assurer une haute disponibilité des services. Si un node ou un serveur tombe en panne, les autres continuent de fonctionner pour maintenir le service en marche. Cette qualité est souvent indispensable dans les applications critiques.
Haute performance
Une conséquence logique de l’utilisation de cinq ordinateurs pour faire le travail d’un seul est d’augmenter la performance. Les environnements edge en tirent parti, car le matériel y est souvent moins puissant et, dans certains cas, ne peut pas traiter les données dans le cloud.
Redondance
Celle-ci est intéressante : même si votre système n’a pas besoin de toutes les autres fonctionnalités présentées, il peut avoir besoin de celle-ci. Lorsqu’une partie de votre application est vitale ou ne doit s’arrêter sous aucun prétexte, un système de cluster peut être une solution viable. Si l’un des nodes tombe en panne, le système de répartition de charge oriente la requête, ou les données, vers un autre ordinateur.
Évolutivité
L’évolutivité est la capacité d’un système à augmenter ou réduire sa capacité selon la demande. C’est probablement l’une des principales raisons pour lesquelles on utilise des clusters, puisqu’ils sont composés de plusieurs nodes que l’on peut ajouter ou retirer sans nuire à la disponibilité du service.
Mettre en place un edge cluster IoT
L’évolutivité, la forte redondance, la haute performance et la haute disponibilité sont autant de bonnes raisons d’implémenter un cluster au sein de votre application IoT, mais comment s’y prendre ?
La première étape consiste à comprendre vos besoins précis. Dans ce cas, il nous faut un système où chaque node peut traiter les données et les requêtes de façon indépendante. Il nous faut aussi un moyen de continuer à ajouter des nodes à mesure que notre application grandit, sans nuire à sa disponibilité.
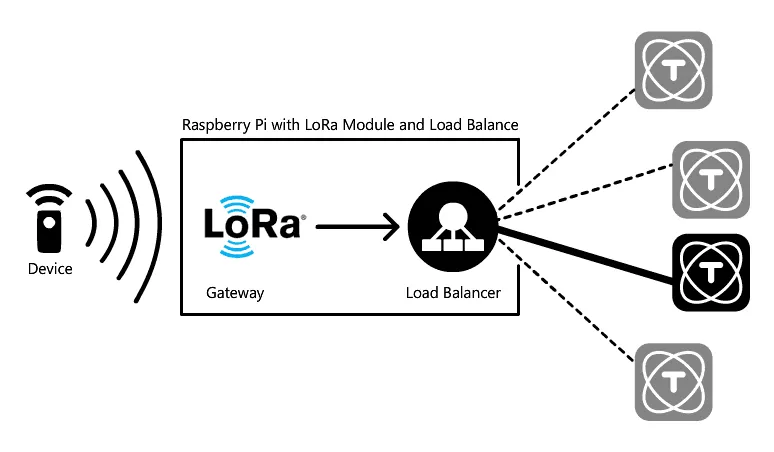
Nous avons mis en place un cluster dans les labs de TagoIO. L’image ci-dessous montre notre cluster avec trois ROCK PI 4 qui font office de nodes exécutant TagoCore et un Raspberry Pi qui exécute un répartiteur de charge (Nginx) et qui sert aussi de gateway LoRa.

Le mode cluster de TagoCore utilise TagoIO comme « head node ». Aucune requête d’appareil n’est envoyée au cloud, et le cluster utilise uniquement le service TagoIO pour synchroniser les réglages et comme passerelle de messages entre les nodes. Déployer un cluster en edge est extrêmement simple ; voyez le schéma ci-dessous :
Comment TagoIO peut-il vous aider ?
Lorsque vous exécutez TagoCore en cluster, toutes les instances sont synchronisées : si vous installez un plugin sur une instance, toutes les autres l’installent aussi. Si vous modifiez une configuration, cette configuration se réplique également sur chaque node de votre cluster.
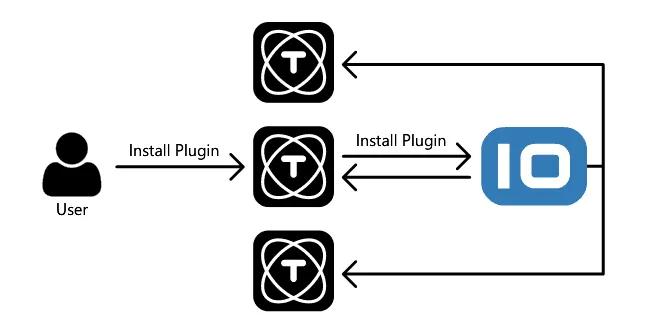
Avec la fonctionnalité de cluster de TagoCore, le service cloud TagoIO se charge de gérer et de synchroniser chaque instance de votre cluster. Cela facilite le déploiement d’un cluster n’importe où, sans la corvée d’installation et de maintenance d’une infrastructure de cluster. Chaque nouvelle instance que vous démarrez avec la fonctionnalité de cluster se synchronise et est prête à recevoir des requêtes.
De plus, l’instance n’a pas besoin de se trouver dans la même infrastructure : vous pouvez donc répartir facilement les instances de votre cluster entre plusieurs régions et différentes machines cloud ou on-premise.
Comme aucune requête d’appareil n’est transmise au cloud TagoIO, vous devrez configurer vous-même un répartiteur de charge. Pour cela, vous pouvez utiliser le service Apache, Nginx, AWS ELB, et d’autres.
Envie d’en savoir plus ?
Pour plus d’informations sur TagoCore, regardez notre webinaire « Installing and Configuring TagoCore on edge devices » et consultez la page de TagoCore.
Les utilisateurs de TagoCore peuvent mettre en place sans effort un cluster au sein de leur environnement IoT on-premise, alors profitez de notre plateforme open source et de ses fonctionnalités de cluster ! Vous voulez aller encore plus loin ? Mettez en valeur les données collectées par vos instances de TagoCore sur des dashboards grâce à la plateforme cloud TagoIO, ou distribuez-les à vos clients via TagoRUN, notre plateforme en marque blanche, sans stocker les données des appareils dans le cloud.
Seul TagoCore vous offre le contrôle des données, la sécurité, la confidentialité, la fiabilité et la simplicité d’usage. Et pour finir : c’est open source !


