
Sie haben wahrscheinlich schon Das große Krabbeln oder einen anderen Zeichentrickfilm gesehen, der zeigt, wie der Zusammenschluss kleiner Teile etwas Außergewöhnliches erschaffen kann. Dieses Prinzip lässt sich auch auf die Welt von Wirtschaft und Technologie übertragen. Ein Edge Cluster ist ein hervorragendes Beispiel dafür, wie CPUs, Server und Edge-Computer zusammengebracht werden, um eine schnellere und zuverlässigere Rechenumgebung zu schaffen.
Da IoT-Anwendungen in der Regel kostengünstige Computer benötigen, die täglich Tausende oder sogar Millionen von Anfragen und Informationen von vielen Geräten verarbeiten, kann ein IoT Edge Cluster viele der Herausforderungen lösen, denen Ihre Anwendung auf ihrem Weg begegnen könnte.
Auch wenn sich Cluster in der Cloud umsetzen lassen, gibt es zahlreiche Gründe, warum Cluster eine ausgezeichnete Option für Edge Computing sind. Dazu gehört, dass Sie mehr Daten verarbeiten und skalieren können, ohne sie in der Cloud zu speichern. Das hilft erheblich dabei, regulatorische Vorgaben und die Datenresidenz einzuhalten.
Ein weiterer wichtiger Faktor ist, dass Edge Cluster dank Redundanzoptionen sowie der Möglichkeit, Nodes hinzuzufügen und auszutauschen, hochverfügbar sein können.
Was ist ein Cluster?
Cluster sind Gruppen unabhängiger Nodes, die zusammenarbeiten, um ein gemeinsames Ziel zu erreichen. Die Nodes sind entweder Computer oder Server, und Sie können einen Cluster mit jedem beliebigen Computer aufbauen, von der einfachsten bis zur fortschrittlichsten Hardware.
Wichtig zu wissen ist, dass Ihre Cluster mit höherer Wahrscheinlichkeit widerstandsfähiger sind und besser funktionieren, wenn alle Computer dieselbe Konfiguration haben.
Wie funktioniert das?
Ein Cluster-System verteilt die Anfragen oder Aufgaben auf verschiedene Nodes und verhindert so, dass das System einen einzelnen Computer überlastet, da es die Arbeitslast ausgleicht.
Das ideale Cluster-System würde alle Computer mit derselben Kapazität arbeiten lassen.
Bei Clustern, die Software mit Client-Server-Architektur beherbergen, etwa HTTP, TCP, UDP, MQTT und Socket, sollte den Nodes in der Regel ein Load-Balancing-System vorgeschaltet sein. Dieses orchestriert die Anfragen, verteilt die Anfragelast mithilfe von Algorithmen auf alle Nodes und prüft deren Verfügbarkeit.
Einige Clustering-Algorithmen verfügen über einen Wahlmechanismus, um einen Head Node zu bestimmen. Der Head Node teilt anschließend Parameter und Einstellungen mit den anderen Cluster-Mitgliedern. Er ist die “Single Source of Truth” für alle Mitglieder, das heißt, wenn sich Einstellungen ändern, müssen sich alle Mitglieder entsprechend anpassen.
Cluster unterscheiden
Es gibt viele Blickwinkel, aus denen Sie einen Computer-Cluster von einem anderen unterscheiden können. Wir sprechen hier nur über ihre Topologie, und die beiden heute am Markt verbreitetsten Cluster-Topologien sind Stern und Mesh.
Eine Mesh-Topologie besteht aus mehreren Nodes, die alle miteinander verbunden sind. Dieser Cluster-Typ kommt zum Einsatz, wenn Sie möchten, dass alle Nodes dieselbe Verfügbarkeit haben, das heißt, wenn einer von ihnen ausfällt, übernimmt ein anderer.
Eine Stern-Topologie besteht dagegen aus einem zentralen Leader Node, der alle anderen verbindet. Diesen Cluster-Typ verwenden Sie, wenn Sie einen Kontrollpunkt für Ihr Netzwerk haben möchten oder wenn nicht alle Ihre Nodes betroffen sein sollen, falls einer von ihnen ausfällt.

Wonach suchen Menschen, wenn sie einen Edge Cluster nutzen?
Wie bereits erwähnt, bieten Cluster viele Funktionen, nach denen Menschen im Edge Computing suchen. Wir haben fünf ausgewählt, um sie zu besprechen: Load Balancing, Hochverfügbarkeit, hohe Leistung, Redundanz und Skalierbarkeit.
Cluster Load Balancing
Load Balancing ist eine Technologie, die die Arbeitslast gleichmäßig auf alle Nodes in einem System verteilt. Sie stellt sicher, dass kein einzelner Node überlastet wird, was entscheidend ist.
Am Markt gibt es viele Optionen für Load-Balancing-Algorithmen und -Techniken. Beispiele wären:
-
Round-Robin: Der einfachste Ansatz; Anfragen werden nacheinander auf die Gruppe von Servern verteilt.
-
Ressourcenbasiert: Hier prüft spezialisierte Software auf jedem Node die verfügbare CPU und den Arbeitsspeicher, um den besten auszuwählen.
-
Gewichtete Antwortzeit: Dieser Algorithmus wählt den Node, der einen Health Check am schnellsten beantwortet.
-
Geringste Verbindungen: Wie der Name andeutet, sendet das System Anfragen an den Node mit der geringsten Anzahl an Verbindungen.
-
Zufällig: Auch hier sagt der Name alles. Dieser Algorithmus verteilt Anfragen zufällig, aber dennoch gleichmäßig auf die Nodes.
Hochverfügbarkeit
Einer der Zwecke von Clustern ist es, eine Hochverfügbarkeit von Diensten zu gewährleisten. Wenn ein Node oder Server ausfällt, arbeiten die anderen weiter, um den Dienst am Laufen zu halten. Diese Eigenschaft ist bei unternehmenskritischen Anwendungen oft unverzichtbar.
Hohe Leistung
Ein logisches Ergebnis davon, fünf Computer für die Arbeit eines einzigen einzusetzen, ist eine höhere Leistung. Edge-Umgebungen profitieren davon, da die Hardware meist schwächer ist und in manchen Fällen keine Daten in der Cloud verarbeiten kann.
Redundanz
Diese ist interessant, denn selbst wenn Ihr System keine der anderen vorgestellten Funktionen benötigt, könnte es diese brauchen. Wenn ein Teil Ihrer Anwendung lebenswichtig ist oder aus keinem Grund stoppen darf, kann ein Cluster-System eine praktikable Lösung sein. Fällt einer der Nodes aus, leitet das Load-Balancing-System die Anfrage oder die Daten an einen anderen Computer weiter.
Skalierbarkeit
Skalierbarkeit ist die Fähigkeit eines Systems, seine Kapazität je nach Bedarf zu erhöhen oder zu verringern. Sie ist wahrscheinlich einer der Hauptgründe, warum Menschen Cluster nutzen, da diese aus mehreren Nodes bestehen, die hinzugefügt oder entfernt werden können, ohne die Verfügbarkeit des Dienstes zu beeinträchtigen.
Einen IoT Edge Cluster umsetzen
Skalierbarkeit, hohe Redundanz, hohe Leistung und Hochverfügbarkeit sind allesamt ausgezeichnete Gründe, einen Cluster in Ihrer IoT-Anwendung umzusetzen, aber wie geht das?
Der erste Schritt ist, zu verstehen, was Ihre konkreten Anforderungen sind. In diesem Fall benötigen wir ein System, bei dem jeder Node Daten und Anfragen unabhängig verarbeiten kann. Außerdem brauchen wir eine Möglichkeit, weiterhin Nodes hinzuzufügen, während unsere Anwendung wächst, ohne ihre Verfügbarkeit zu beeinträchtigen.
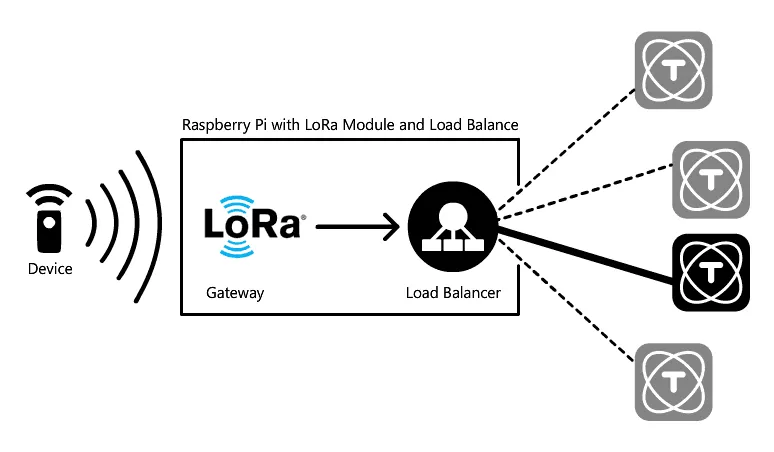
Wir haben in den Labs von TagoIO einen Cluster umgesetzt. Das Bild unten zeigt unseren Cluster mit drei ROCK PI 4, die als Nodes arbeiten und TagoCore ausführen, sowie einem Raspberry Pi, der einen Load Balancer (Nginx) ausführt und gleichzeitig ein LoRa-Gateway ist.

Der Cluster-Modus von TagoCore nutzt TagoIO als “Head Node”. Keine Geräteanfrage wird in die Cloud gesendet, und der Cluster verwendet den TagoIO-Dienst nur, um Einstellungen zu synchronisieren und als Message-Bridge zwischen den Nodes. Es ist außerordentlich einfach, einen Cluster am Edge bereitzustellen; sehen Sie sich das Diagramm unten an:
Wie kann TagoIO helfen?
Wenn Sie TagoCore als Cluster betreiben, sind alle Instanzen synchronisiert. Das bedeutet, wenn Sie ein Plugin in einer Instanz installieren, installieren es alle anderen Instanzen ebenfalls. Wenn Sie eine Konfiguration ändern, wird diese Konfiguration auch auf jeden Node in Ihrem Cluster repliziert.
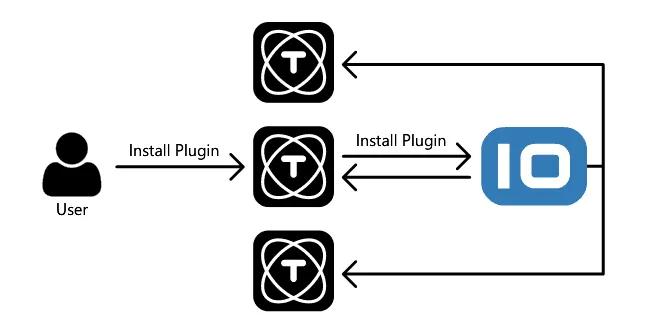
Mit der Cluster-Funktion von TagoCore ist der TagoIO-Cloud-Dienst für die Verwaltung und Synchronisierung jeder Instanz in Ihrem Cluster zuständig. Das macht es einfach, einen Cluster überall bereitzustellen, ohne den Aufwand für Einrichtung und Wartung der Cluster-Infrastruktur. Jede neue Instanz, die Sie mit der Cluster-Funktion starten, synchronisiert sich und ist bereit, Anfragen zu empfangen.
Außerdem muss sich die Instanz nicht in derselben Infrastruktur befinden, das heißt, Sie können Ihre Cluster-Instanzen problemlos über Regionen und verschiedene Cloud- oder On-Premise-Maschinen verteilen.
Da keine Geräteanfrage an die TagoIO-Cloud weitergeleitet wird, müssen Sie das Load Balancing selbst einrichten. Dafür können Sie den Apache-Dienst, Nginx, AWS ELB und andere verwenden.
Möchten Sie mehr erfahren?
Weitere Informationen zu TagoCore finden Sie in unserem Webinar “Installing and Configuring TagoCore on edge devices” und auf der Seite von TagoCore.
TagoCore-Nutzer können mühelos einen Cluster in ihrer On-Premise-IoT-Umgebung umsetzen, nutzen Sie also unbedingt unsere Open-Source-Plattform mit Cluster-Funktionen! Möchten Sie noch weiter gehen? Präsentieren Sie die mit Ihren TagoCore-Instanzen erfassten Daten auf Dashboards über die TagoIO-Cloud-Plattform oder verteilen Sie sie mit TagoRUN, unserer White-Label-Plattform, an Ihre Kunden, ohne Gerätedaten in der Cloud zu speichern.
Nur mit TagoCore haben Sie Datenkontrolle, Sicherheit, Datenschutz, Zuverlässigkeit und einfache Bedienung. Und nicht zu vergessen: Es ist Open Source!


